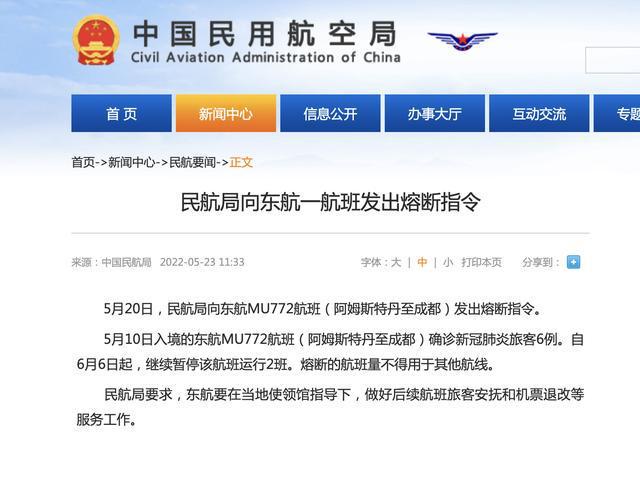
破解手機屏幕使用時的一大難題 蘋果新專利曝光
使用墨鏡或太陽鏡看手機屏幕時,常常會出現部分屏幕變得黑漆漆一片的情況,給使用帶來了不便。蘋果最近獲得了一項專利,可以解決這個問題。
2023-03-24
近期有很多工作比如Alpaca、Vicuna、Koala等論文宣稱通過收集到的大量chatgpt output,在基于開源大模型如LLaMA上進行微調后的模型就接近甚至超過chatgpt效果。有些看熱鬧不嫌事大的媒體渲染諸如“復制chatgpt,僅需100美元“,”開源大模型超過chatgpt“啦。但事實真的如此嗎?來自UC Berkeley的研究團隊在The False Promise of Imitating Proprietary LLMs這篇論文中分析的這些模型的效果,并給出結論”還差的遠呢“。相信這些經驗能指導我們怎么做大模型,以及大模型的核心到底是什么。讓我們一睹為快把。
這里有兩個概念后面會被反復使用到,因此提前定義下:
 (相關資料圖)
(相關資料圖)
proprietary model: 標題中的proprietary LLMs指的就是chatgpt這種閉源的專有模型,參數不進行開放,我們只能獲取到模型的輸出信息,而無法模型參數、生成過程中詞語的概率等信息。
imitation model: 指的是通過模仿proprietary model的輸出而進行訓練的開源模型。
大模型的壁壘在于訓練的foundation model的好壞,這要求我們我們訓練更強,更大的基礎模型。而在style、persona方面的差異性則不是壁壘,因為別的模型可以通過很少的樣例就能學習到這些信息。這點也說明了為啥現在所有的大公司都在自己訓練基礎大模型,因為這才是真正的關鍵。
眾包的人工評測是不靠譜的(未來應該怎么評測大模型好壞依然是questionable的,或者需要極強的專家知識,比如需要MIT的博士用專業領域知識評估),很多imitation model 很容易就模仿到chatgpt輸出答案的風格,即style,而沒有達到chatgpt輸出答案的正確認識、即factuality。因為很多情況下眾包人員缺乏領域知識,而無法判斷兩個模型輸出是否有事實錯誤,因此傾向于認為兩個模型是打平,甚至是好于chatgpt的。
開源模型和chatgpt仍然具有很大的差距,尤其在涉及factuality的問題上,比如需要領域知識,以及coding,reasoning,math problem solving等問題上。
imitation model 自身的能力仍需加強作者定義了兩種imitation,一種是task-specific的imitation,這種是在特征任務上收集足夠多的chatgpt的輸出,然后訓練小模型,這種imitaion目的是想要在特定任務,特定領域上達到chatgpt的效果。一種是broad-coverage imitation,就是利用人們在網上公開的自己的問題以及chatgpt的回復,這些數據集一般包含千羅萬象,什么問題都有,這種imitation是想要在整體效果上達到chatgpt效果。現在公開的大多模型屬于后一種。
broad-coverage imitation常見數據集有:
ShareGPT,大約90K用戶和ChatGPT的對話信息。
HC3,大約27K用戶的提問以及ChatGPT的回答信息。
Discord ChatGPT Bots, 大約10K來自社區(reddit等)提供的用戶和ChatGPT的交流信息。
對于task-specific imitation,作者構造了6K的QA pair,其中問題是來自Natural Questions這個數據集,里面大多是一些關于維基百科的事實性問題,而回答都來自ChatGPT,這個數據集稱為NQ-Synthetic。
對于broad-coverage imitation,作者將上面提到的三個數據集進行清洗、去重后構建了一個新的稱之為ShareGPT-Mix的數據集。
作者在這兩個數據集上對從1B到13B大小的模型進行finetune,來探究imitation model的效果究竟如何。
在NQ-Synthetic數據finetune后效果有持續變好,并且在模型參數量上去后,效果有持續的逼近chatgpt,說明如果是想在某個領域上達到chatgpt的效果,那么imitation這種方法是可行的。
在ShareGPT-Mix上finetune后在問答效果反而下降了,這可能是模型學習chatgpt的輸出風格而折損了部分性能。
提升imitation model 訓練的數據量不會提升效果,可以看到一開始的時候模型就飽和了,右上圖的結果也說明了在broad-coverage imitation訓的太多反而會降低在natural question 數據集上的效果。
提升imitation model 的參數量可以顯著的提升模型的效果,說明基礎模型的效果才是關鍵。
趨勢和上面的評測是一致的,說明在一定程度上用gpt-4作為裁判來判定chatgpt和imitation model的效果好壞是可行的。
d一個關于強化學習的問題,chatgpt回答的很好,而imitation model回答有很多的事實錯誤。其中紅色部分是事實錯誤部分,可以看到imitation model回答的像模像樣,但是錯誤百出。如果不是對強化學習有足夠的了解的評估人員,可能就被騙了。
這篇論文最有含金量的部分就在討論部分,我們以結論為主,感興趣的同學可以看原文的分析。
現有的開源模型和chatgpt的差距還很大,主要是在需要factuality的任務上,比如reasoning, math problem solving,一些專業問題上。
現有open-source LLM最大的limitation就是基礎模型的能力太弱了,只有13B參數量想要達到chatgpt的效果是遠遠不夠的。因此開源社區應該努力訓練更大更好的開源模型,而不是finetuning更多chatgpt的output。
在broad-coverage數據集上finetune并不會提升模型對于事實性問題回答的準確性,甚至可能降低效果。側面也印證了大模型的能力主要是來自于預訓練階段,和Meta的LIMA: Less Is More for Alignment這篇論文的假設一致。
在task-specific數據集上finetune可以提升相應領域上的效果。
imitation model學習到的是style而不是content。
大模型如何評估將變得很困難,因為已經驗證目前的眾包人工評測已經是不可行的,而不能總讓gpt-4評測吧,比如我就要超過gpt-4,怎么能讓gpt-4既當運動員又當裁判呢?
imitation model繼承了teacher model的safety以及toxicity style,因此如果已經訓練好的一個強大的foundation model,而沒有錢像openAI 那么豪雇幾百個專家做safety & alignment,那么可以嘗試用imitation的方式對齊。
pre-training階段是LLM能力的主要來源,finetuning只是一個輕量級的方法來引誘出這些知識,此處再次cue到LIMA。
如果是采用imitation這種方法,那么很可能會加劇幻覺hallucination問題,因為imitation model要強行學習proprietary model的輸出,而這些輸出可能原本就再它能力之外。
如果偏偏就想用imitaion的方式獲得chatgpt的性能,作者說那就不是簡簡單單用幾十上百K的數據微調這么簡單,應該覆蓋方方面面的知識,這個量級可能和需要的預訓練數據量級相當。(: 有這個量級的數據我還finetune啥
大模型的壁壘在于foundation model訓練的好壞,因此使勁堆積起來模型參數量,模型訓練token數量讓你的基礎模型更強大吧。
如果兩個公司用同樣的fondation model, A公司在輸出style和persona等方面作了優化,那么B公司很快可以通過模仿A公司的輸出來白嫖到A公司的優化,因此這方面的積累是技術壁壘。
人工評測有很大問題,但目前還不知道怎么解決。
標簽:



Intel最新處理器Arrow-S曝光 最高可達24核
配置拉滿的電競神機 雷神ZERO2023大黃蜂發布
真我10Pro系列發布 首發量產2160Hz超高頻調光技術
阿富汗塔利班組建正規軍
薩赫勒地區反恐形勢面臨新變數
北約北擴加劇歐洲安全風險
貴州畢節七星關區百所學校創辦百個“紅軍班”
湖北省孝感軍分區組織軍地聯合應急救援研究性演練
青藏高原等區域將新設一批國家公園
河北省承德軍分區退役軍人擔綱教練主力